 企业邮箱
企业邮箱 开发者中心
开发者中心

 企业邮箱
企业邮箱 开发者中心
开发者中心![[公式]](/upload/images/20220420/6378607262851890703598751)
![[公式]](/upload/images/20220420/6378607262901890755512665)
![[公式]](/upload/images/20220420/6378607262906578211498572)
![[公式]](/upload/images/20220420/6378607262923770089212959)
![[公式]](/upload/images/20220420/6378607262930597723726284)
![[公式]](/upload/images/20220420/6378607262934703118712192)
融资火热、量产躁动 脑机接口“落地前夜”:当马斯克按下量产键,中国企业正用“介入式”突围医疗刚需
2026.06.18


发布时间:2022.04.20 17:29 访问次数: 作者:李竞捷
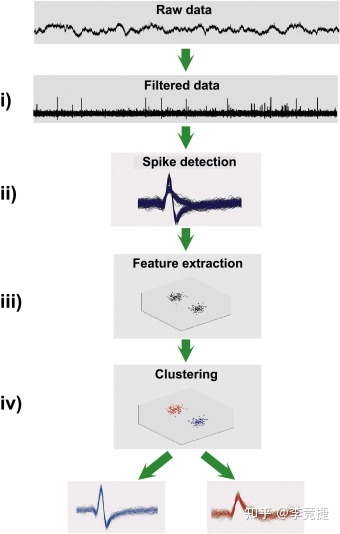
返回列表记录分析神经元活动是神经科学研究的基础,也就是电生理的研究。电生理研究的基础就把这些活动从原始的电极电压信号抓出来。Spike Sorting就是做这个事情的:从原始的电压信号中根据不同神经元放电信号的不同特征精确分离,从而从一组电压信号对单个神经元活动进行估计。
我前面一年时间用硅电极记录了好多的电生理的数据,现在每天都要不停的跑spike sorting,我主要用的是现在性能比较好,高通量记录用的比较广泛的Kilosort软件。我在大规模使用kilosort的同时也花了一些闲暇时间啃一啃它的开源代码,终于对Kilosort这个软件背后蕴含的算法有了一些了解,所以想要也跟大家分享一个“手撕kilosort”系列文章,给大家讲一讲Kilosort这个软件到底是怎么又快又好对神经元信号进行提取和分类的。
首先还是简单介绍一下spike sorting这个事情。我们记录到的脑活动信号其实是非常模糊粗糙的,好比在一个有好多人喧闹的会场(有很多很多神经元的脑组织),放一个话筒记录整个会场的声音。但是我们想要分离A同学在啥时候说话(神经元A何时放电);B同学啥时候说话什么的,就需要有专门的探测、分类算法来完成了。因为不同的人离话筒距离不一样,不同的人说话的声音也不一样,我们可以根据这些信号的特征进行分类识别,来得到对每个人(神经元)活动的探测。所以在电生理信号中我们根据记录到的信号波形首先要进行强度的探测,看看这时候有没有神经元活动。探测到神经元发放活动后再根据这个信号的强度、宽度等不同特征做自动的聚类,每一个神经元就是一簇,这样就可以根据他们的这些特征从原始的信号里找出对应波形,从而得到这个电极附近每个神经元活动的精确情况了。
Spike Sorting算法拿原始的电压数据,最后返回一些不同的神经元:发放动作电位的时间点。我们可以利用这些时间点去和当时给动物呈现的刺激、以及动物的反应来对比,从而研究这个脑区如何编码、控制等功能的。
Spike Sorting的步骤一般是这样:从原始电压进来,1) 第一步是滤波,去掉低频的噪声和局部场点位,只保留高频的部分(因为神经元所产生的spike都是非常快非常高频的)。2) 然后使用高频的部分信号,探测那些尖峰毛刺一样的信号(一般就是拉一个阈值来探测。那就是神经元的放电); 3)抓出来尖峰的信号,对齐到一起,提取出来一些特征:一般是通过PCA降维自动提取特征,或者一些很基本的特征比如高度,宽度等;4)根据提取的特征做聚类分析,一般相同神经元这些特征都会很接近,不同神经元可能会有比较大的差别,通过聚类把这些一簇一簇的spike分类开来,从而得到最终结果:这样的波形是一号神经元,那样的波形属于二号神经元等等。吧局部记录到的电信号转化为单个神经元层面的放电活动信号。这个过程如下图:
近些年电生理记录技术的发展真的是突飞猛进,在现在神经科学研究所流行使用的硅电极中,电极数量可以到几百通道,每秒3万次电压记录,并且电极位点的位置都是固定的(固定在硅片雕刻的针上),神经元临近的几个通道都可以记录到这个神经元的信息,可以很好的提高对神经元分类的精度和同时记录到神经元的数量。但是这种高通量记录所带来的数据量也是非常大的。Kilosort就是在这种情况下应运而生被大家所广泛使用:它非常高效,用GPU大规模并行计算,降维以及分类算法也非常先进,非常擅长处理超大通量的神经电生理信号。
Kilosort是我现在这个学校一个搞神经科学特别有名的实验室做出来的(UCL Cortex Lab),主要作者是Marius Pachitariu(数学背景),他最近已经在HHMI Janelia拿到教职啦。他们做的这个工具除了配置起来折腾显卡驱动,CUDA,编译器坑有点多非常麻烦之外真的是非常优秀。欧美系统神经科学界可谓人人皆知而且人人都在用。运行速度非常快,结果也很可靠。Kilosort有几大优势:1)是运行效率非常高,基本上所有的运算部分都用GPU大规模并行运算实现;2)引入了很多新颖的算法,比如利用神经元信号的降维压缩、卷积模版匹配检测Spike,以及通过优化专门设计的损失函数进行聚类的分析等,有很多独特的优势;3)利用硅电极记录位点拓扑已知的特点,开发了建模电极飘变的功能(drift),可以补偿记录过程中电极运动带来的信号变化。让结果更稳定。
Spike Sorting可以划分为预处理的主要就是滤波这一块 (进行spike探测之前)。在预处理这里,Kilosort是这样操作三大步骤: 去共模(common reference removal)->滤波(filtering)->白化(Whintening)。
去共模比较容易,即每个记录位点减去记录整体的波动(可以移去叠加在所有通道的噪声,比如运动,一些电磁干扰等)。在这里kilosort用每个记录位点的电压减去所有通道电压的中位数,来实现一个比较稳定的去共模。看这里:gpufilter.m
% subtract the mean from each channeldataRAW = dataRAW - mean(dataRAW, 1); % subtract mean of each channel% CAR, common average referencing by medianif getOr(ops, 'CAR', 1)
dataRAW = dataRAW - median(dataRAW, 2); % subtract median across channelsend学过数字信号处理的同学应该对滤波器的特性都有所了解。滤波器的设计有很多要点和需要妥协的地方,比如说IIR滤波器结构很简单,但是相位上会容易造成更多影响(或者说是群延时问题)。如下图,简单的巴特沃斯滤波器会在截止频率附近有比较大的群时延,这会引起信号的一些畸变问题:(40 samples在电生理记录里几乎就是1个spike的宽度,超过了1ms,这是不可忽略的!)

在spike sorting这种任务下,我们需要一个尽可能尽可能简单节省算力的滤波器,同时需要它在通带足够平稳,不要有相位的delay,尽量不会对信号造成畸变。不过我们不需要信号的实时性,因为全部是离线处理的,所以这里有一个非常巧妙的办法:就用最简单的巴特沃斯滤波器(利用其高频通带平稳的特点),正做一遍反做一遍,让相位的影响相互抵消,这就是matlab的filtfilt函数的精髓了:通过牺牲因果性来达到零相位滤波的目的!kilosort就是这样操作,不过因为他尽量用gpu操作,如下代码。gpufilter.m
% next four lines should be equivalent to filtfilt (which cannot be used because it requires float64)datr = filter(b1, a1, dataRAW); % causal forward filterdatr = flipud(datr); % reverse timedatr = filter(b1, a1, datr); % causal forward filter againdatr = flipud(datr); % reverse time back看一下实际效果呢:蓝色是用零相位filtfilt滤波,黄色是相同滤波器普通处理。我们可以看到黄色还是有很明显的畸变的(主要看spike发放的rebound回弹部分,黄色明显大很多),这是不好的。
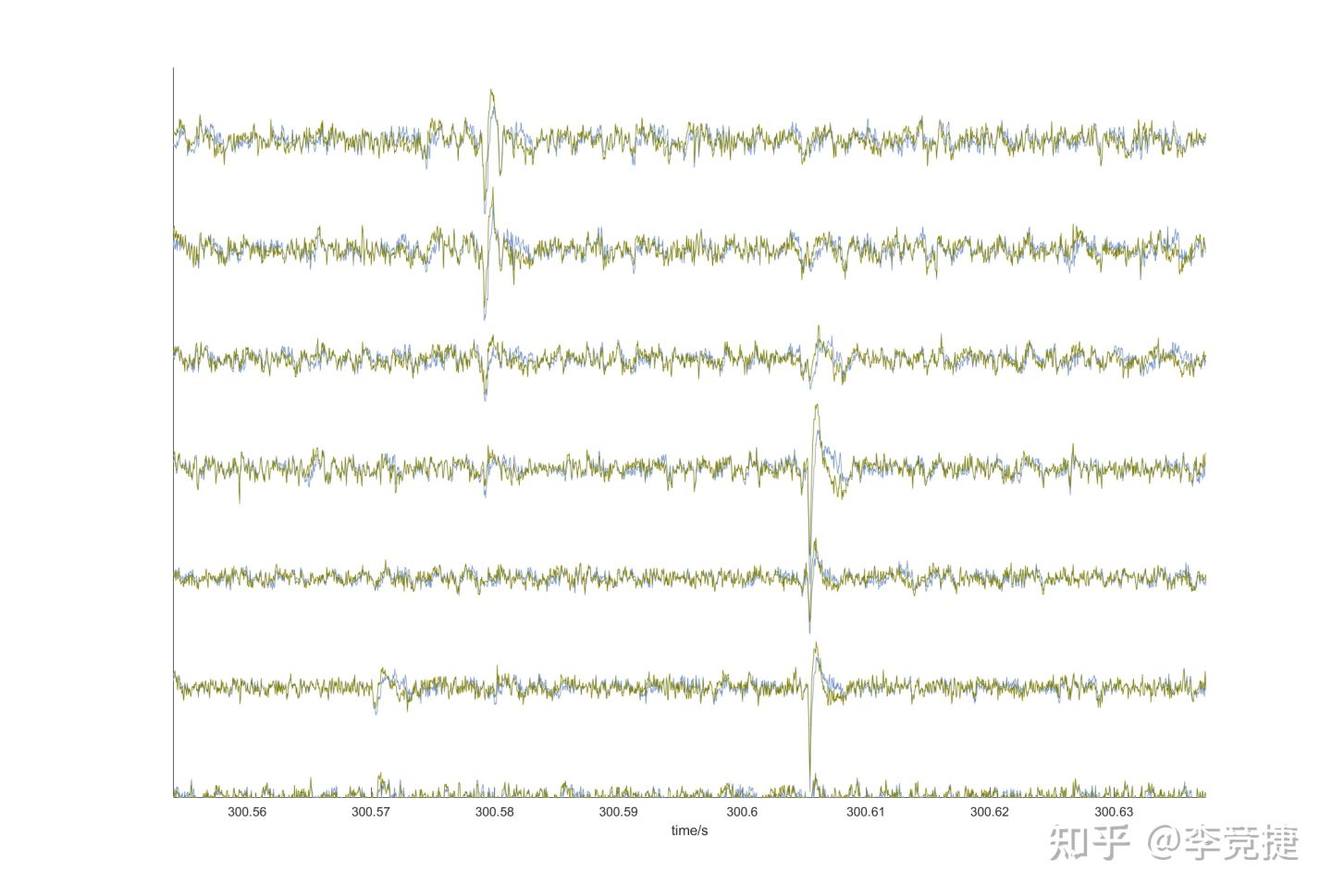
简单总结一下滤波器方面,kilosort只用了最简单的3阶巴特沃斯IIR,来追求快一些的速度和平坦的通带。通过正向一边反向一遍抵消相位的影响(参考matlab的filtfilt函数)。
最后来看看kilosort的ZCA信号白化。
“白化”是数据预处理很重要的环节。白化就是让数据的分布更接近白噪音,尽量减少不同通道数据相关的成分,并且让各个通道所贡献的幅度也尽量均匀一致。
我们知道神经元的发放本身是一种转瞬即逝的随机信号,虽然说临近通道都可能收到相同神经元的电活动信号,但是他们的波形也一定是不一样的。而在绝大部分时间,神经系统大范围整体活动的信号 以及叠加在所有的通道的噪声(他们可能因为幅度不同无法被去共模的部分减掉)都是有一定相关性的,那么我们希望通过白化,进一步的去掉这些相关性,从而可以把真正的神经元活动这样转瞬即逝的随机信号更加好的凸显出来,从而可以让后续的算法更容易收敛到一个稳定的结果。
从数学上来说,白化基本就是利用协方差矩阵对原始信号的分布做一些调整,让有相关性的部分互相抵消,让幅度大小不均匀的部分更加均匀一致,比如说我们对原始信号求一个协方差 ![[公式]](/upload/images/20220420/6378607262833140176356947)
![[公式]](/upload/images/20220420/6378607262837827532342855)
![[公式]](/upload/images/20220420/6378607262844077165856180)
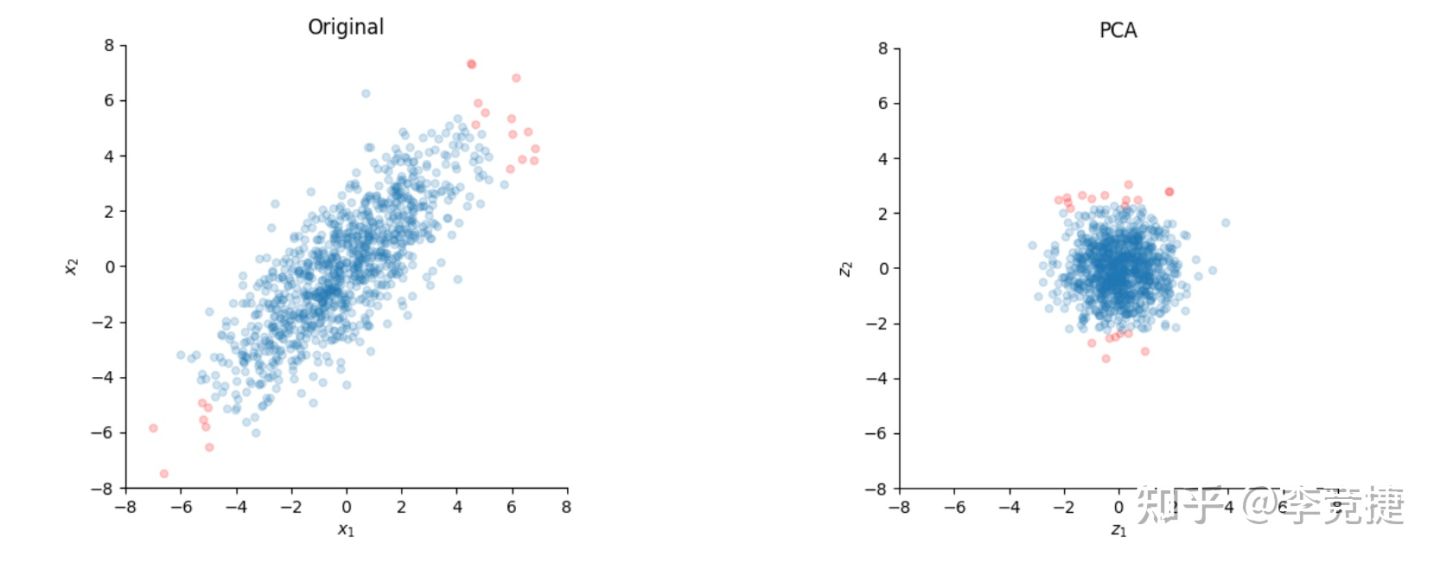
这就是PCA白化,如果你要纯粹做classification任务的话这样其实也行,不过对于spike sorting的话这样会影响spike在不同channel幅度的分布,可能本来在这个channel的spike会被旋转到另一个channel去,所以我们可以再用一个U相乘把他旋转回到原来的角度,保留缩放:
效果如下图:引自这里

在kilosort中,ZCA白化在这里完成:whiteningFromCovariance.m
核心代码是这些,可以看到通过分解协方差矩阵,再按照公式做缩放旋转操作。
[E, D] = svd(CC); % covariance eigendecomposition (same as svd for positive-definite matrix)
D = diag(D); % take the non-zero values from the diagonal
Wrot = E * diag(1./(D + eps).^.5) * E'; % this is the symmetric whitening matrix (ZCA transform)下面我们再来看一下在真实数据上kilosort这个ZCA的旋转缩放矩阵长什么样:
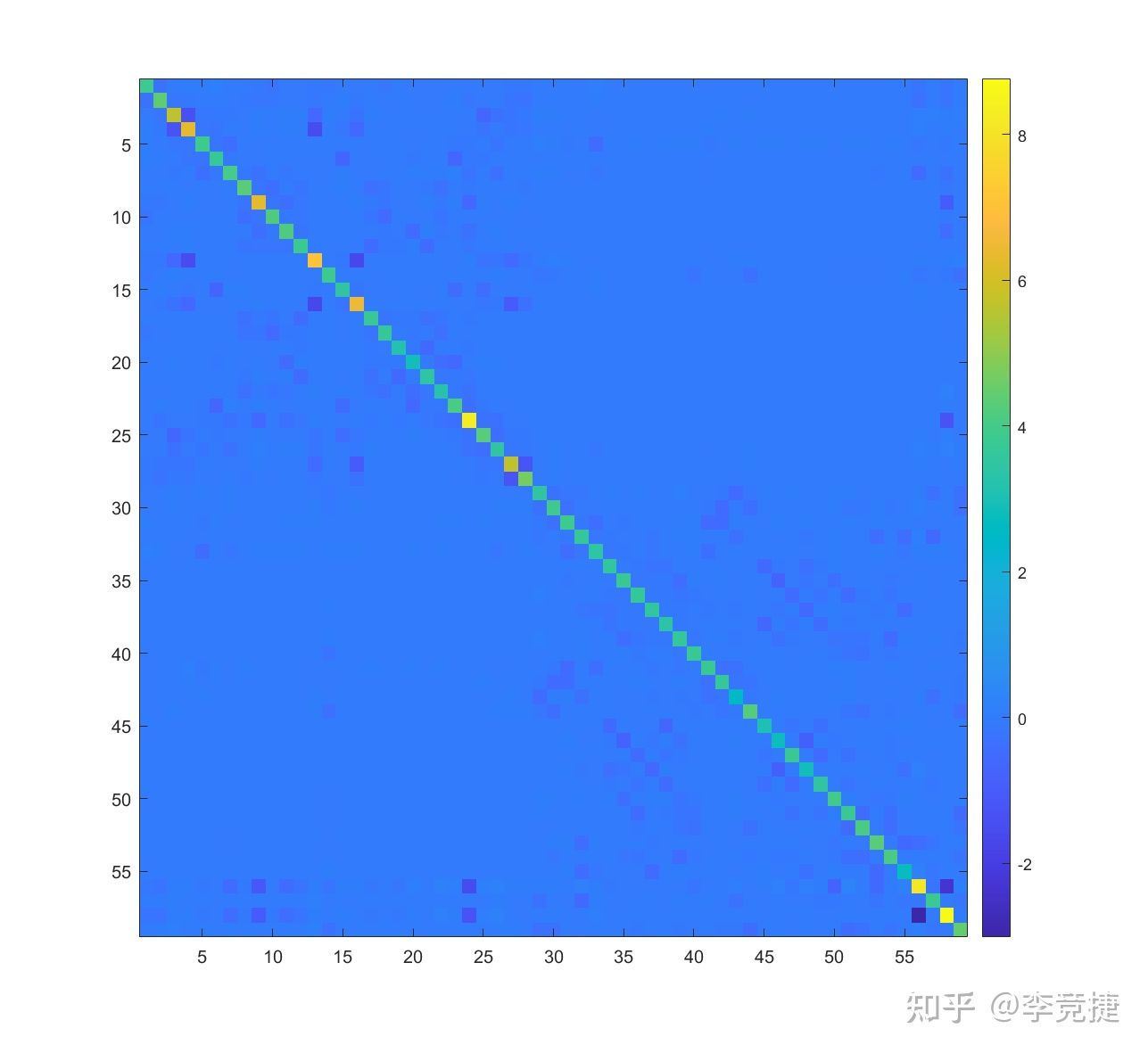
基本上可以看到在非对角线的部分(不同channel之间的调整)都比较微弱,实际上不同channel之间的相关性都比较弱,最主要的调整还是在对角线(每个channel本身的缩放),这主要是根据这些channel本身的方差对齐大小做调整,本身噪声大的channel会被缩小幅度,减少其对后续算法的影响。
在ZCA白化之后,kilosort还有一个整体扩大信号幅度的操作(大概是扩大200倍),这是因为kilosort为了节省内存其实是用int16而非最详细的double格式来存数据的,因为spike幅度很小,为了避免运算舍入的影响直接扩大两个数量级。
最后简单再总结一下kilosort预处理部分都干了什么:中位数去各个通道共模成分 -> 零相位滤波尽量保留波形的形状 -> ZCA白去相关凸显spike特征 -> 整体放大避免舍入误差。
现在因为有了高通量硅单极记录的通道数量越来越多,那么如果还是一个通道一个通道的处理,计算可能太过庞大,不过好在spike其实是比较稀疏的,一般只会出现在临近几个通道,利用这个特性,我们可以对spike做一些压缩处理,只用几个维度的信息来节省内存和算力。
比如我们利用一个宽度为91个采样(大概是3ms)的窗口来看一个spike(n)。如果我们有64个通道,那么我们可以用一个91x64的矩阵来表示。这个矩阵包含了这个spike波形的信息,我们定为。对于这个spike ![[公式]](/upload/images/20220420/6378607262861263744570566)
我们对An求SVD: ![[公式]](/upload/images/20220420/6378607262865952209556474)
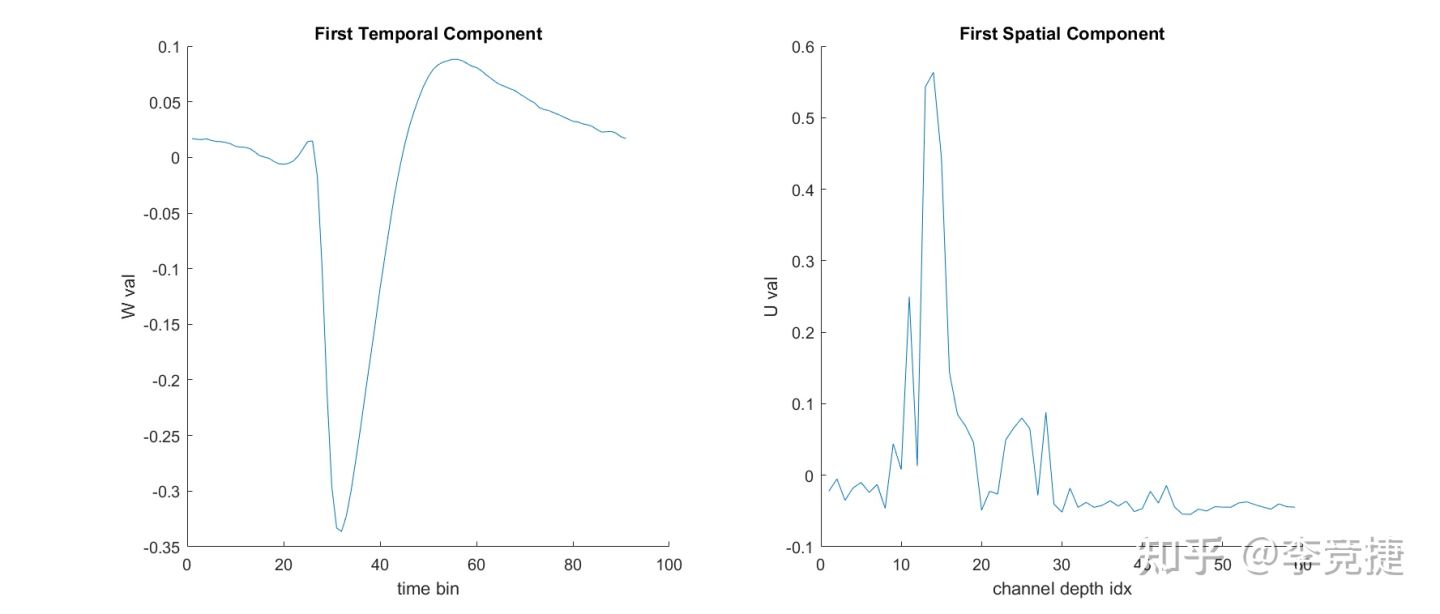
上图左边就是W的第一列了,我们可以看到基本就是一个spike的形状,他是从所有的channel里提出来的这个spike的主干。右边的U呢,我们可以看出来它直接可以看出来这个spike在不同channel上空间的分布,最中间离得最近的比较大,边上的比较小。这就是吧Spike分解为了时间和空间的两个成分。
Sigma则是一个对角矩阵(对角之外都是0),可以理解为对W(每列)和U(每行)的权重,并且是按照降序排列的。我们如果拿一个真实的spike的波形进来观察的话,我们会发现Sigma的值是这样的:
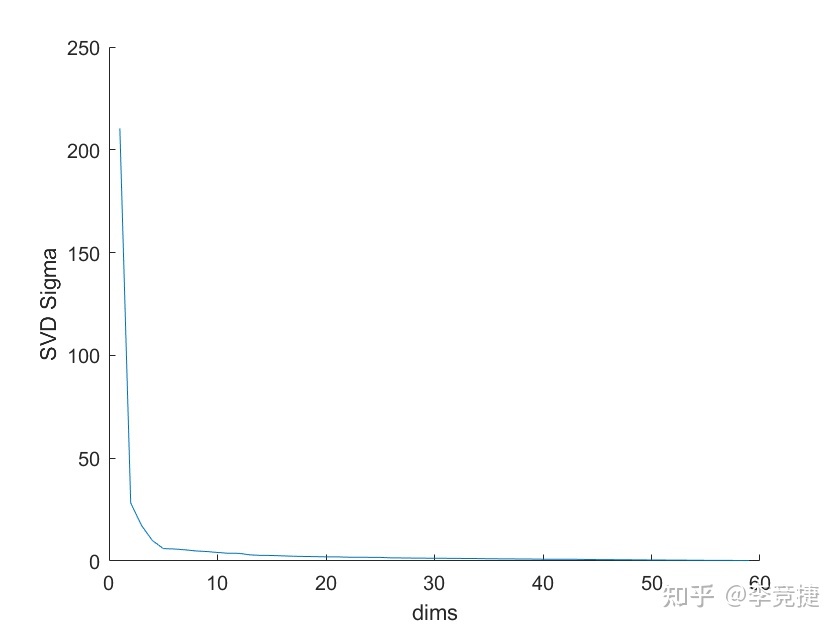
基本就是前几个非常巨大,后面的可以忽略不计。所以在kilosort中算法一般只取前三个维度。吧这个Sigma后面的全部去掉,把W和U在第三个行或者列后面的内容也全部扔掉,重新乘回去来重建这个Spike。在这里大家可以参考kilosort 1.0版本的这个文件:get_svds.m 在这里它一上来就对spike做了SVD,然后在后面只取前几个指定的维度:
[Wall, Sv, Uall] = svd(gather_try(dWU), 0);
...
mu = sum(Sv(1:Nrank).^2).^.5;
...
W = Wall(:,1:Nrank);
U = Uall(:,1:Nrank);我们也可以自己找个spike简单plot一下压缩前和压缩后对照的效果,就直接调用他的函数:
[W, U, mu] = get_svds(raw_waveform_mat, 3); %only got first 3 dims
wave_recontruct = (W*U').*mu;
figure;
subplot(1,2,1)
plot(bsxfun(@plus,raw_waveform_mat(:,plotting_channels),channel_posi(plotting_channels,2)'),'Color',[114 147 203]/255)
subplot(1,2,2)
plot(bsxfun(@plus,wave_recontruct(:,plotting_channels),channel_posi(plotting_channels,2)'),'Color',[114 147 203]/255)我随便找了一个spike效果是这样:
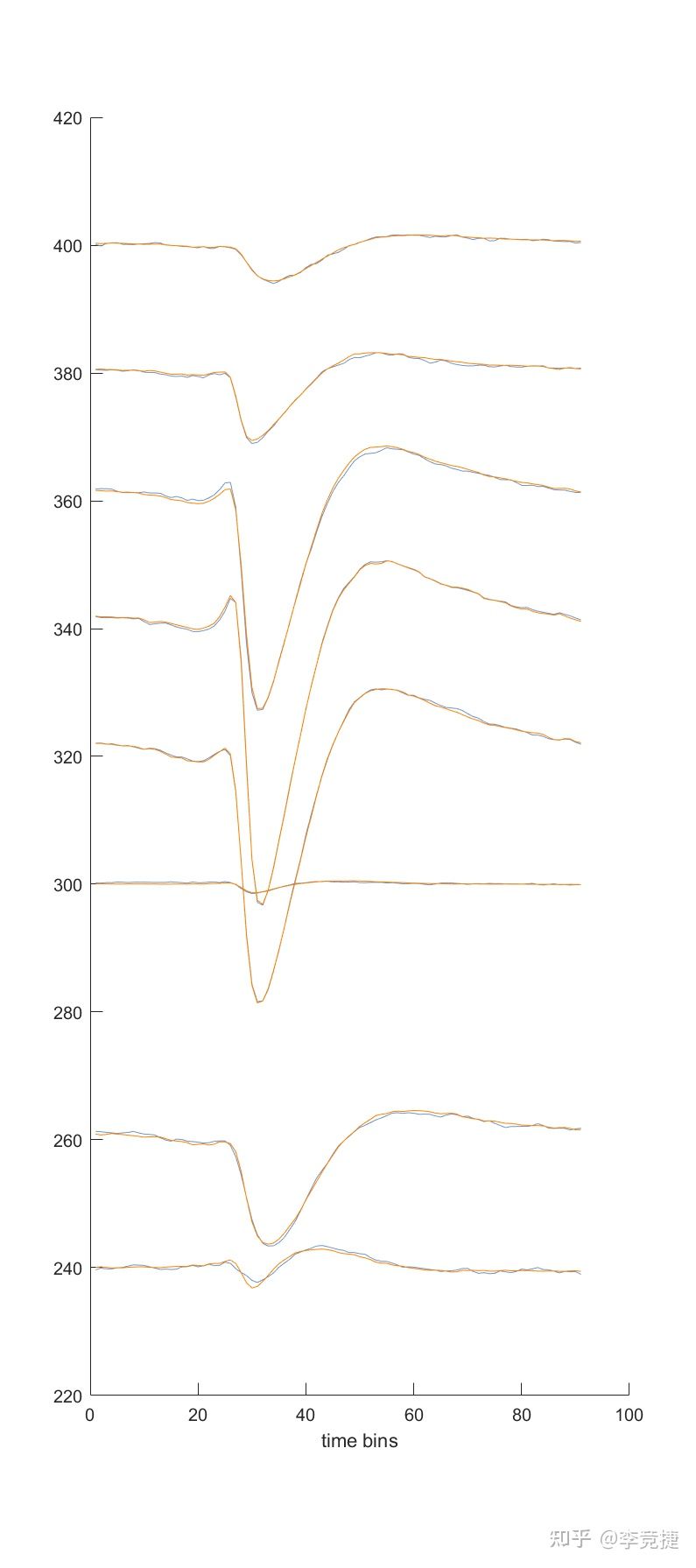
在这里面黄色是reconstruct后的,蓝色是原始波形。我们可以看到他们的相似度实际上是非常非常高的,只有一点点细节不太一样:就是在很边缘的通道上面可能重建会有一些区别。所以用这个跑后续分析完全是够用的,不过如果要计算Spike的2d参数的话,建议还是不要用压缩重建的spike。
模板匹配是kilosort的核心,也是kilosort优于其他spike sorting非常重要的一个元素。传统的探测spike的方法其实一般就是在经过高通滤波的原始电压信号以上加一个阈值,如果有超过阈值的这种波动我们就把它当作一个spike发生了,然后抓出来这个spike的峰值对其做进一步操作。比如说下面这个图(Sukiban et al., 2019)
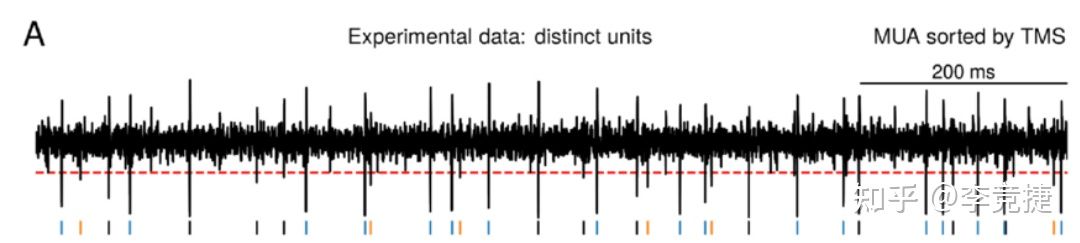
不过这样做有一个很显而易见的缺点:如果两个spike靠得太近甚至几乎同时发生,这种spike就会被错误的探测成一个,比如说下面这种spike:
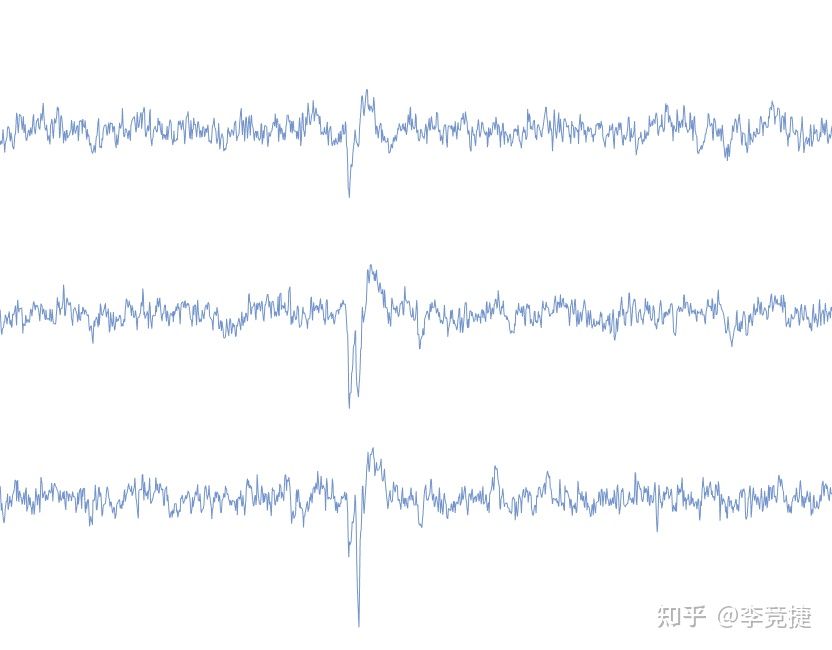
尽管说神经元的Spike是比较稀疏的,而且一个神经元发放之后会有一个短暂的不应期,但是在高密度低阻抗这样的高通量的记录条件下这样的情况还是会有的,因此这样的传统方法会有一定的miss的情况。
Kilosort对于这个情况的解决方法非常巧妙:它假设神经细胞的这种spike在电极上都是线性叠加的,所以如果用一个spike的模板,连续的去扫描整个时域信号(在每一个时间点处都做叉乘这样的求和,来定量化模板和信号的重叠),那么就可以得到一个时域的匹配强度的结果,再用这个做精确一些的阈值分析,那么我们的miss一些离得比较近的spike的情况就会比较少了。kilosort的benchmark的结果进一步印证了这一点::
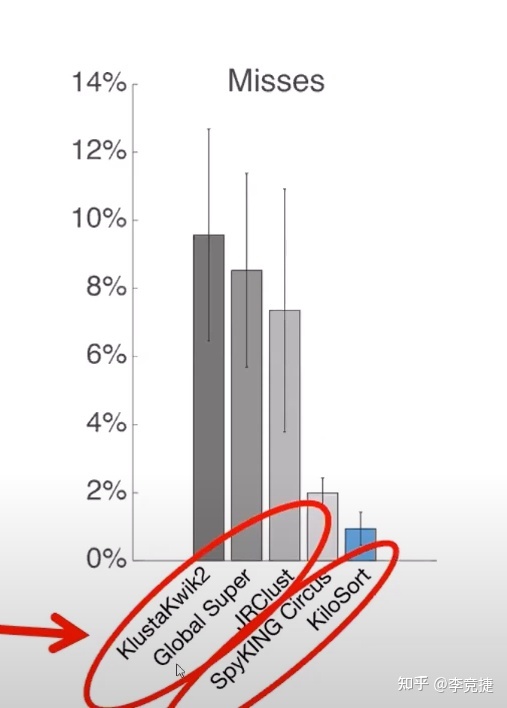
上面这个图是主流的一些Spike Sorting软件对一个电生理数据集的表现结果,我们可以看到左边三个使用传统的阈值方法的sorting工具miss都比较多,而Kilosort和spyking circuits这种使用模板匹配方法的则明显少得多。
在数学上,这种连续时间的叉乘比较,叫做卷积。因此直接拿这个spike模板和时间信号进行卷积,我们就可以用卷积算法直接得到模板匹配的结果。在kilosort论文(Pachitariu et al., 2016) 公式6介绍了这个卷积模板匹配的公式和优化:V原始电压数据(很多亿个samples x 通道数量) ![[公式]](/upload/images/20220420/6378607262887828844256769)
改变一下运算数据,我们可以先用U(空间降维模板),去和原始电压信号V进行卷积,相当于首先对电压信号进行空间(通道)尺度的降维,然后再拿降维后的电压信号和spike的时间降维模板W去卷积。
这样一来可以把本来很多个通道(有可能上百个)降低到3个通道,可以非常显著的降低运算量,从而加快运算速度。另一个加快运算速度的方式是用高度并行的方法完成这个卷积。根据卷积的性质,时间尺度的两个序列卷积等于频域尺度上两个序列相乘。而快速傅里叶变换算法是非常高度并行的成熟算法,根据这个特性,Kilosort(CPU运算版本)先进行傅里叶变换,相乘,再逆傅里叶变换回到时域。大家可以参考这个函数:mexMPregMUcpu.m的这一部分:
fdata = fft(data, [], 1);
proj = real(ifft(fdata .* fW(:,:), [], 1));时域信号的降维运算在这个函数之前的主函数完成:fitTemplates.m
% project data in low-dim space
data = dataRAW * U(:,:);在Kilosort的GPU CUDA版本中,卷积运算直接使用高度并行的GPU多线程计算完成,主要在这里的Conv1D函数:mexMPregMU.cu
while (tid0<NT-Nthreads-nt0+1){
if (tid<nt0*NrankMax) sdata[tid%nt0 + (tid/nt0)*(Nthreads+nt0)] =
data[tid0 + tid%nt0+ NT*(bid + Nfilt*(tid/nt0))];
#pragma unroll 3 for(nid=0;nid<Nrank;nid++){
sdata[tid + nt0+nid*(Nthreads+nt0)] = data[nt0+tid0 + tid+ NT*(bid +nid*Nfilt)];
}
__syncthreads();
x = 0.0f;
for(nid=0;nid<Nrank;nid++){
#pragma unroll 4 for(i=0;i<nt0;i++)
x += sW[i + nid*nt0] * sdata[i+tid + nid*(Nthreads+nt0)];
}
conv_sig[tid0 + tid + NT*bid] = x;
tid0+=Nthreads;
__syncthreads();
}在上面这个代码框里,一个thread完成一个卷积时间点的叉乘运算,每次循环完成的数量取决于Nthreads。Nrank是SVD降维的最终维度,默认是3个维度,也是在每个thread的运算内完成的。
完成了卷积以后,kilosort会得到一个时间点x n_模板数量x n个压缩通道(3个通道, 降维后通道)的模板匹配值,约高就代表有spike波形匹配的很好的信号产生。把这三个通道直接横向压缩为一个通道(求和,因为我们不关注匹配的空间分布,只需要知道时间点和对应的模板assignment),得到的结果拉两个阈值比较(一个动态阈值,防止一次波峰识别为多个spike时间点,一个基础阈值,设定一个基线),最终找出来一些spike发生的时间点:这个时候得到的模板匹配长下面这样:
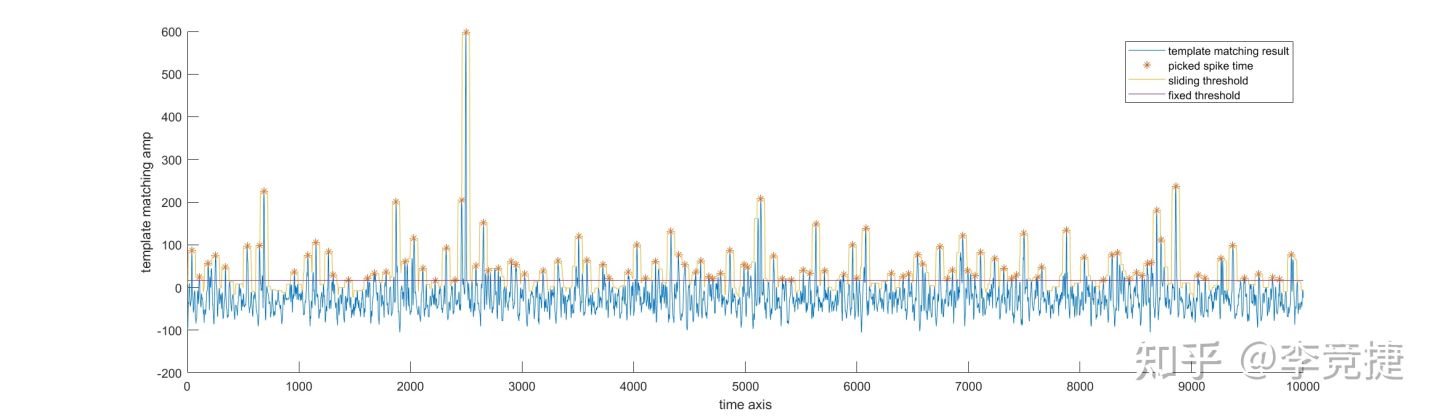
这一段的代码也在mexMPregMUcpu.m这里面:(Ci是经过一系列变换后的卷积值,这些变换不改变相对大小关系)
[mX, id] = max(Ci,[], 2);%在这里合并多个降维后通道maX = -my_min(-mX, 31, 1);%动态阈值,每次取得极大值后固定一小段序列id = int32(id);st = find((maX < mX + 1e-3) & mX > Th*Th);%用动态阈值和基线阈值卡出来spike发生的时间点st最后总结一下这一章:kilosort利用了SVD把很多个电极通道的spike模板做降维处理,然后直接和电压信号进行卷积(调整运算速度)。通过卷积完成模板匹配,通过模板匹配的结果拿出来做阈值比较后获得每个spike的时间点,这样的方法比较快速且精确。
相比经典的spike sorting直接用经典聚类算法比如k-means之类,kilosort最终聚类用了一个非常Fancy的优化损失函数的方法。kilosort这个损失函数的设计是非常简单理想的:就是通过spike的模板结合spike的时间点,去生成一个重建的电压信号(V0)(在白噪音上的特定时间点直接叠加spike信号,可以解释为以spike模板去和spike时间点进行卷积运算),再拿真实的电压信号(V)减去这个重建的理想电压信号 ![[公式]](/upload/images/20220420/6378607262914393838241143)
![[公式]](/upload/images/20220420/6378607262919080614227051)
这个cost函数的假设条件如下:
首先是完成优化之后。V = V0 + 白噪声。电压信号是重建的电压+白噪声
V0建模为不同Spike模板K再特定时间点s的叠加
上面这个公式看起来复杂,其实不太复杂,i是每个记录的通道,t是时间。s(k)是spike模板k的发放时间,K(i,t)就是每一个spike模板,然后把不的K移动到相应的s(k)这个地方,最后xk是spike的幅度factor,可以控制模板k的缩放变化,用来建模记录到的电信号的漂变。最后一个条件是幅度因子xk符合正态分布
那么最后的损失函数L就是这样:
![[公式]](/upload/images/20220420/6378607262940952677927345)
![[公式]](/upload/images/20220420/6378607262951890457426578)
![[公式]](/upload/images/20220420/6378607262956579753412486)
这个损失函数同时优化四类变量,其实是不可能完成的,不过有的变量其实可以直接根据当前的条件求出来,比如说spike的时间s,spike时间s来自于上一节提到的卷积模板匹配。spike的幅度xk也来自于模板匹配(在spike的时间那一个的提取)的结果。
每一组波形的更新是动态迭代的,根据上一组优化后的波形和这一组模板匹配后从原始数据重新抓出来的波形提取,再根据新得到的spike数量加权更新,这里对应论文内的公式3,在线优化spike模板A:

上述内容都可以在 mexMPregMUcpu.m 找到一一对应的动态更新。kilosort把所有的数据分成大概两分钟长度的一小节一小节(batch),应用这种动态更新的算法不算的更新模板, spike时间等,最后得到一个比较稳定的优化的解准备作为sorting的结果。
我们可以回到mexMPregMUcpu.m,这里能直接找到在线更新各种参数的细节。
inds = bsxfun(@plus, st', [1:nt0]');
dspk = reshape(dataRAW(inds, :), nt0, numel(st), ops.Nchan);
dspk = permute(dspk, [1 3 2]);
...
for j = 1:size(dspk,3)
dWU(:,:,id(j)) = pm * dWU(:,:,id(j)) + (1-pm) * dspk(:,:,j); %公式3,在线更新spike模板
x(j) = proj(st(j), id(j));%spike幅度直接更新
Cost(j) = maX(st(j));%损失函数
nsp(id(j)) = nsp(id(j)) + 1;
end不过还有一个需要注意的细节其实是这个动态更新的损失函数是如何进行初始化的:在这里kilosort初始化的过程和传统的spike sorting是类似的:通过取一小段样本的数据,进行阈值检测然后做k-means聚类分析完成,再以这部分结果,在所有数据的结果上做优化各种参数(核心目标依然是优化损失函数:即预测电信号和真实电信号的差),从而达到最后的结果。
k-means初始化聚类这一部分在最终的模板优化之前,在2.0版本中,出现在这里:extractTemplatesfromSnippets.m这个文件的末尾位置。只做10次kemas迭代,wTEMP就是初始化的模板。
for i = 1:10
% at each iteration, assign the waveform to its most correlated cluster
cc = wTEMP' * dd;
[amax, imax] = max(cc,[],1);
for j = 1:nPCs
wTEMP(:,j) = dd(:,imax==j) * amax(imax==j)'; % weighted average to get new cluster means
end
wTEMP = wTEMP ./ sum(wTEMP.^2,1).^.5; % unit normalize
end不过除了这些主干内容之外,kilosort还有漂变(Drift)建模部分,2.0和2.5版本更新了聚类迭代部分的算法,我会后面有机会还会继续和大家更新。
需要额外注意的是kilosort运行结束后返回的template是模板,kilosort并不会直接给你每个unit的平均波形,如果大家需要用平均波形进行一些后续运算比如SNR,waveform metrics之类的话需要去返回原始文件提取。
请问大家看问上述内容以后,kilosort在运行过程中自动plot出来的图片结果大家可以看懂了吗?比如说下图的第一排的左右两个图?
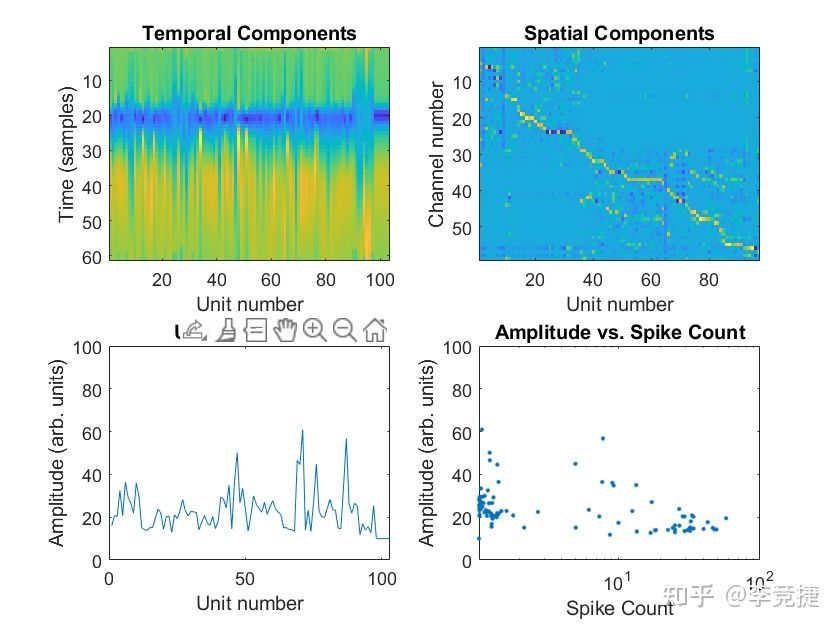
其实这个图直接对应于SVD降维后的空间成分和时间成分,也就是W和U的第一行或者第一列。其实也是他们最主要信息所在的维度,从时间成分可以直接看出来spike的形成,比如在第20个左右sample的时候低下去,30左右可以看到有rebound回来,这个是竖着看的横轴是算法跑出来最终的spike数量,大约是100多个。右边Spatial Components呢基本就可以看这个unit主要在哪个channel。
kilosort是一个非常出色的开源的spike sorting包。基本上国际上做高通量电生理的都会只选择kilosort (相信没人用offline sorter做neuropixel的吧。。)。kilosort的算法确实和传统的spike sorting非常不一样。模板匹配+在线优化是kilosort的核心。利用GPU高度并行的运算也真的是非常快的。我们64通道俩小时的数据用3090显卡五分钟左右就可以直接跑,基本上和从存储服务器拷下来的速度差不多了。
不过kilosort的CUDA配置确实是个大坑。我以前用ubuntu系统在真正掌握到CUDA怎么配置之前一顿乱试各种驱动和compiler之类的,经常还会直接把ubuntu的图形界面整崩溃,在这方面也积累了不少心得。另外电生理实验处理数据吧kilosort跑起来也只是一小部分。kilosort结束之后,可以选择进行手动的manual curation(使用phy),也可以跳过curation的步骤。从kilosort源文件提取波形信息,然后可以使用一些metrics参数化的去标定每个神经元簇的质量,自动化筛选神经元等等。为了这些后续工作我也写了大量的代码去流程化的进行处理。
Pachitariu, M., Steinmetz, N. A., Kadir, S. N., Carandini, M., & Harris, K. D. (2016). Fast and accurate spike sorting of high-channel count probes with KiloSort.Advances in neural information processing systems,29.
Rey, H. G., Pedreira, C., & Quiroga, R. Q. (2015). Past, present and future of spike sorting techniques.Brain research bulletin,119, 106-117.
Whitening with PCA and ZCA 白化的教程和例子
Sukiban, J., Voges, N., Dembek, T. A., Pauli, R., Visser-Vandewalle, V., Denker, M., ... & Grün, S. (2019). Evaluation of spike sorting algorithms: Application to human subthalamic nucleus recordings and simulations.Neuroscience,414, 168-185.
原文链接:https://zhuanlan.zhihu.com/p/499879539
5492388.png)
3984080.png)
5951721.png)
4584645.png)
4485013.png)
7941567.png)


TEL: 021-63210200
业务咨询: info@oymotion.com
销售代理: sales@oymotion.com
技术支持: faq@oymotion.com
加入傲意: hr@oymotion.com
上海地址: 上海市浦东新区半夏路100弄788幢
合肥地址: 合肥市蜀山区望江西路69号西湖国际广场
珠海地址: 珠海市高新区唐家湾镇鼎业路82号B05栋5楼

微信号:oymotion
扫描二维码,获取更多相关资讯

